Installation biffo
Die Installation von biffo sollte ohne große Abhängigkeiten von statten gehen. Für die Verwendung bzw. dessen Nutzung sind im Vorfeld einige Voraussetzungen zu schaffen. Im Folgenden wird beschrieben wie eine „einfache“ Installation lauffähig ist. Das Beispiel beruht auf einer CentOS 7 Version bei der im Vorfeld noch ein „yum update“ durchgeführt wurde. Die Installation erfolgte unter dem Benutzer „root“, daher entfällt das vorgesetzte „sudo“.
Folgende Komponenten werden in dieser Beschreibung verwendet:
– yum-utils
– Tesseract 4.x
– wget
– Java 17
– Tomcat 7 (oder vergleichbar)
– PostgreSQL >= 9.x
– OpenSearch 2.x
Installation Tesseract 4.x
Leider ist in dem aktuellen CentOS Repos nur die Version 3.x verfügbar. Nachdem biffo nicht mit 3.x getestet wurde, sollte daher die Version 4.x installiert werden.
Version 4.x wurde von dem Entwickler Alexander Pozdnyakov auf einem Open-Suse Repos bereitgestellt. Dieses Repository wird über folgende Befehle eingebunden:
Falls yum-utils noch nicht vorhanden sind:
yum install yum-utilsRepository hinzufügen:
yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/CentOS_7/
Hinzufügen des Repository-Keys:
rpm --import https://build.opensuse.org/projects/home:Alexander_Pozdnyakov/signing_keys/download?kind=gpg
Update der lokalen Installation mittels yum update:
yum updateInstallation Tesseract mittels yum install:
yum install tesseract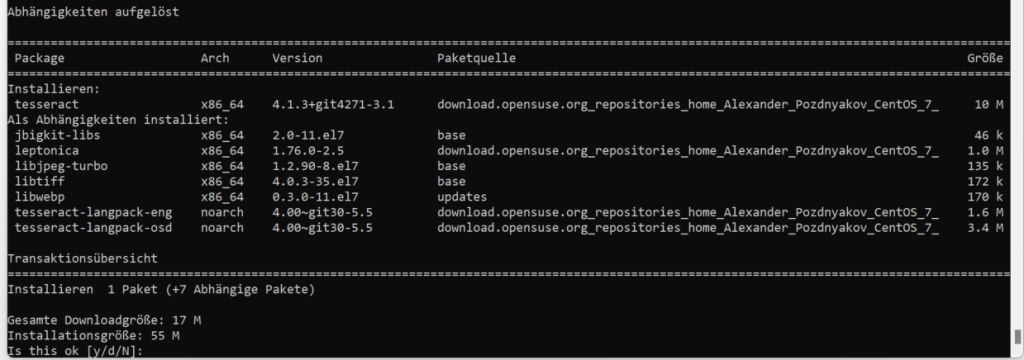
Wichtig ist hierbei das es sich um Version 4.x handelt. Die Aufforderung kann in diesem Fall mit „y“ bestätigt werden.

Installation passendes Language-Pack mittels yum install:
yum install tesseract-langpack-deuNach der Installation sollte überprüft werden, ob Tesseract auch gestartet werden kann:
tesseract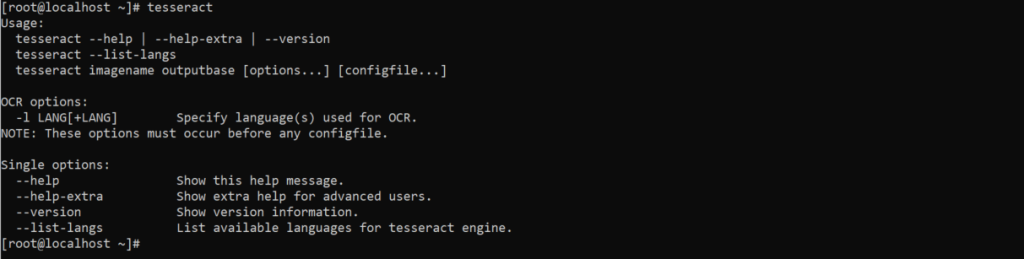
Zum Abschluss sollte auch überprüft werden, an welcher Stelle die Installation und das Daten-Verzeichnis abgelegt wurden. Die Werte sind wichtig für die anschließende Konfiguration.
cd /
find * | grep tessdata
Installation Java >=17
Leider gestaltet sich die Installation von Java nicht mehr so einfach. Durch den Verzicht auf ein RPM seitens Oracle, muss man sich mit einigen Handgriffen beschäftigen.
Falls wget noch nicht installiert sein sollte:
yum install wgetIm Beispiel wird als Installationsort der Ordner /opt verwendet.
cd /optDownload der Java Binaries von java.net:
wget https://download.java.net/java/GA/jdk17.0.2/dfd4a8d0985749f896bed50d7138ee7f/8/GPL/openjdk-17.0.2_linux-x64_bin.tar.gz
Entpacken des Archivs:
tar xvf openjdk-17.0.2_linux-x64_bin.tar.gzKopieren des JDK’s an einen allgemeinen Ort:
mv jdk-17.0.2/ /opt/jdk-17/Installation Tomcat > 7.x
Download des Tomcat-Application Servers mittels wget.
wget https://archive.apache.org/dist/tomcat/tomcat-7/v7.0.99/bin/apache-tomcat-7.0.99.tar.gzEntpacken des Archivs:
tar xvf apache-tomcat-7.0.99.tar.gzUser, Gruppe und entsp. Rechte hinzufügen:
groupadd tomcat
useradd -g tomcat tomcat
chown -R tomcat:tomcat apache-tomcat-7.0.99Erstellung tomcat.service Datei im Verzeichnis /etc/systemd/system
Diese Datei wird entsp. dem Verzeichnis indem sich der entpackte Tomcat Server befindet angepasst.
Der Service kann dann über systemctl enable tomcat.service eingetragen und über den Befehl systemctl auch gestartet werden.
[Unit]
Description=Tomcat
After=syslog.target network.target
[Service]
Type=forking
User=tomcat
Group=tomcat
WorkingDirectory=/opt/apache-tomcat-7.0.99
Environment="JAVA_HOME=/opt/jdk-17"
Environment="CATALINA_HOME=/opt/apache-tomcat-7.0.99"
Environment="CATALINA_OPTS=-Xms1024M -server"
ExecStart=/opt/apache-tomcat-7.0.99/bin/startup.sh
ExecStop=/opt/apache-tomcat-7.0.99/bin/shutdown.sh
[Install]
WantedBy=multi-user.targetInnerhalb der Datei server.xml müssen noch die Parameter „ maxHttpHeaderSize=“65536“ “ und „ maxPostSize=“4194304“ “ gesetzt werden. Anderenfalls, kann es Probleme bei großen PDF Dokumenten während der Anzeige, Bearbeitung, etc. … geben.
Die Datei server.xml befindet sich im Verzeichnis conf des entpackten Tomcat-Archivs.

Bevor getestet wird ob der Tomcat erreichbar ist, sollte die Firewall-Regeln für den notwendigen Port 8080 geöffnet werden:
firewall-cmd --zone=public --add-port=8080/tcpWenn man die Regel nicht bei jedem Server-Neustart erneut eingeben möchte, so sollte die Regel mit einem „–permanent“ versehen werden:
firewall-cmd --zone=public --add-port=8080/tcp --permanentDer Service wird mittels dem Befehl systemctl dem System bekannt gemacht und kann auch direkt gestartet werden.
systemctl enable tomcat.service
systemctl start tomcat.serviceDer Zugriffstest kann dann mit einem normalen WebBrowser erfolgen:
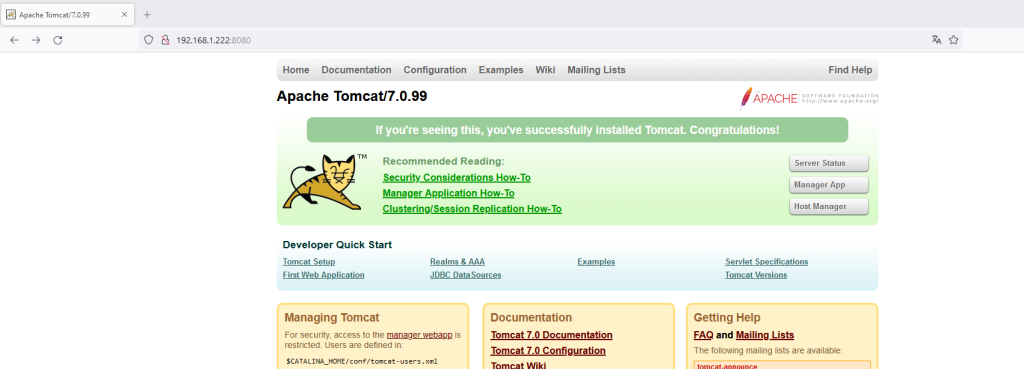
| Befehl | Info |
| systemctl enable tomcat.service | Bekanntmachen des Tomcat-Dienstes |
| systemctl status tomcat.service | Zeigt den aktuellen Zustand des Dienstes an. |
| systemctl start tomcat.service | Starten des Tomcat-Servers |
| systemctl stop tomcat.service | Stopp des Tomcat-Dienstes |
Installation PostgresSQL
Die Installation der notwendigen PostgreSQL Datenbank erfolgt einfach vom System heraus.
yum install postgresql-server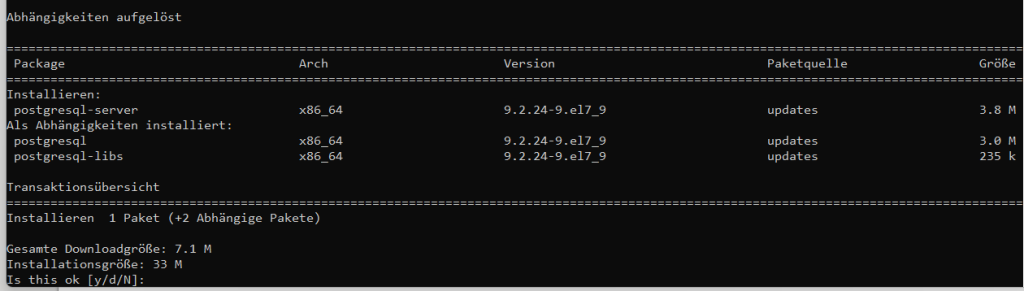
Anmerkung: In dem Beispiel wird die im CentOS hinterlegte Version 9.2.x verwendet. Es sind auch neuere Versionen möglich.
Um die Datenbank in den Betrieb zu bekommen, müssen noch folgende Befehle ausgeführt werden:
postgresql-setup initdb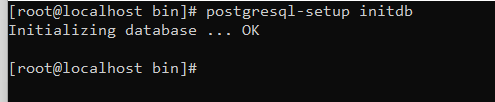
In der Datei pg_hba.conf muss der Authentifizierungsmethode noch auf „trust“ umgeschaltet werden. Anderenfalls ist kein Login seitens unserer Applikation möglich.
Die Datei „pg_hba.conf“ befindet sich im Verzeichnis:
cd /var/lib/pgsql/data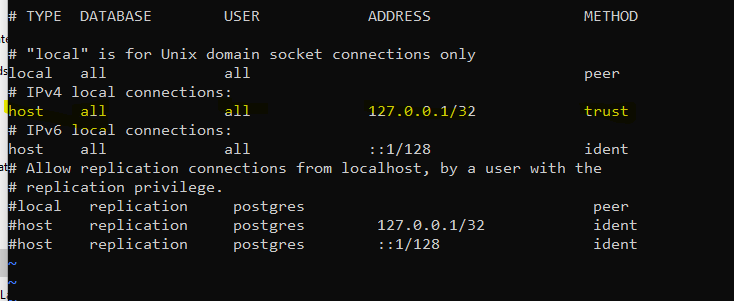
Die Datenbank kann nach einer Bereitstellung des des Dienstes:
systemctl enable postgresql.serviceüber
systemctl start postgresql.servicegestartet werden.
Ob die PostgreSQL Installation korrekt durchgeführt wurde, kann über den Befehl:
systemctl status postgresql.servicegetestet werden.
Die Rückgabe sollte in etwas wie folgt aussehen:
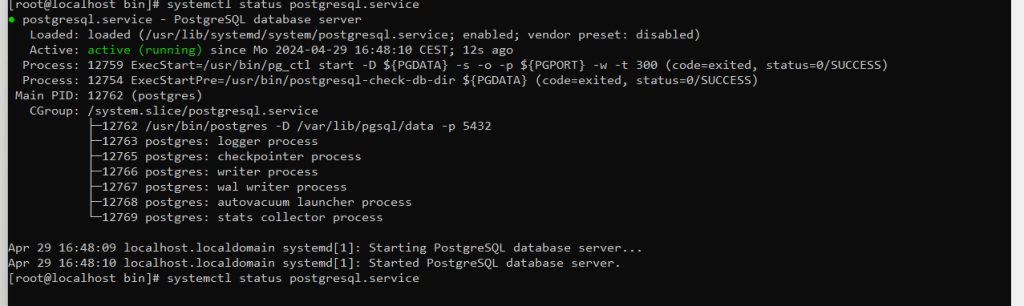
biffo benötigt eine existierende Datenbank und einen passenden Benutzer. Beides wird mit der psql Shell durchgeführt.
su postgresDanach öffnet sich die zugeordnete Shell und der Befehl psql öffnet eine Shell zur Datenbank.
psql
Der Befehl create database dms ertellt dann die Datenbank, die für die spätere Konfiguration notwendig ist.
create database dms;
Wie bereits erwähnt, erfolgt die Installation sowohl mittels root aber auch mit dem default postgres user (DB-Admin). Daher sollte direkt das Passwort des PostgreSQL Users geändert werden:
\password
Die Shell kann über \q mit anschliessendem exit verlassen werden.
Installation OpenSearch
Für das Suchen und Finden von Dokumenten, wird Open-Search verwendet.
Download des OpenSearch Servers mittels wget:
cd /opt
wget https://artifacts.opensearch.org/releases/core/opensearch/2.0.1/opensearch-min-2.0.1-linux-x64.tar.gzDas entpacken erfolgt wie bisher mittels tar:
tar -xvzf opensearch-min-2.0.1-linux-x64.tar.gzIn dem entpackten Verzeichnis, wird auch direkt der Server ausgeführt. Dieses beinhaltet auch das Verzeichnis für die bzw. den Index:
cd opensearch-2.0.1
mkdir dataUser, Gruppe und Rechte hinzufügen:
groupadd opensearch
useradd -g opensearch opensearch
chown -R opensearch:opensearch /opt/opensearch-2.0.1Erstellung opensearch.service Datei im Verzeichnis /etc/systemd/system
Diese Datei wird entsp. dem Verzeichnis indem sich der entpackte Opensearch Server befindet angepasst. Die folgende Konfiguration als Service wurde unter Anpassungen der Ordner aus dem Internet übernommen.
[Unit]
Description=Opensearch
Documentation=https://opensearch.org/docs/latest
Requires=network.target remote-fs.target
After=network.target remote-fs.target
ConditionPathExists=/opt/opensearch-2.0.1
ConditionPathExists=/opt/opensearch-2.0.1/data
[Service]
User=opensearch
Group=opensearch
WorkingDirectory=/opt/opensearch-2.0.1
ExecStart=/opt/opensearch-2.0.1/bin/opensearch
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65535
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
# Allow a slow startup before the systemd notifier module kicks in to extend the timeout
TimeoutStartSec=75
[Install]
WantedBy=multi-user.targetDas Eintragen als Service erfolgt analog wie beim Tomcat-Server mittels systemctl. Allerdings mit dem neu erzeugten Service-File.
| Befehl | Info |
| systemctl enable opensearch.service | Bekanntmachen des Opensearch Services |
| systemctl status opensearch.service | Zeigt den aktuellen Zustand des Dienstes an. |
| systemctl start opensearch.service | Starten des Opensearch-Servers |
| systemctl stop opensearch.service | Stopp des Opensearch-Dienstes |
Installation und Konfiguration DMS-Applikation
Nachdem die Voraussetzungen für den Betrieb geschaffen wurden, muss die Datei DmsWeb.war in das webapps Verzeichnis des Tomcat-Servers kopiert werden.
Das Deploy-Verzeichnis befindet sich innerhalb des Tomcat-Servers:
cd /opt/apache-tomcat-7.0.99/webapps/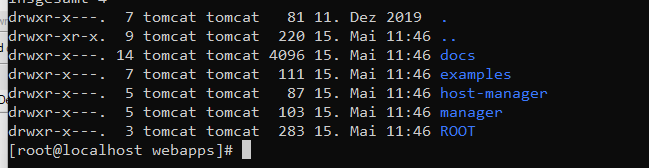
Nachdem die Datei „DmsWeb.war“ in das Verzeichnis kopiert wurde, kann über einen Browser mittels der URL: http://<SERVER-IP>:<SERVER-PORT>/DmsWeb auf die Applikation zugegriffen werden:
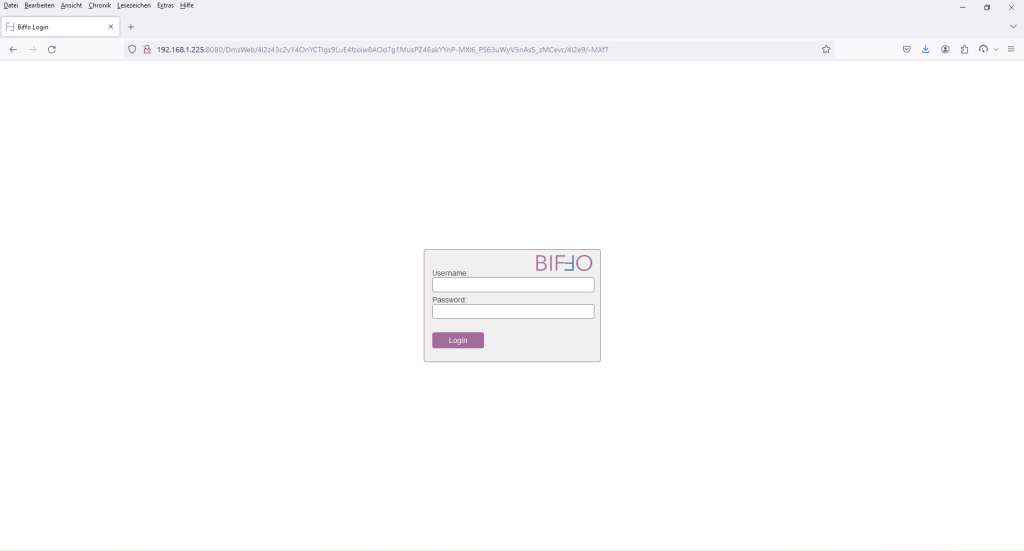
Der Username und das Passwort lauten: setup/setup
Im Anschluss öffnet sich folgendes Fenster für die Datenbankkonfiguration:
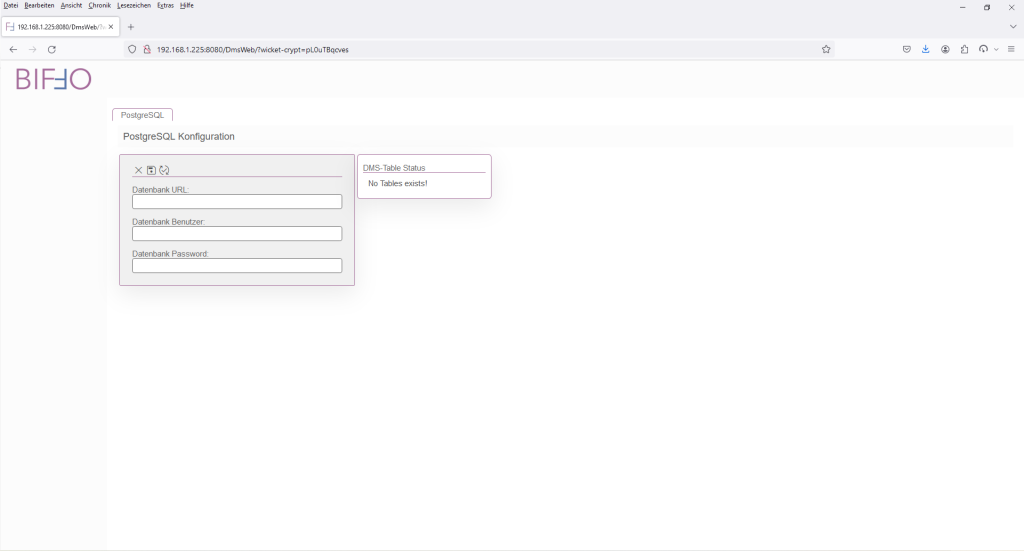
Folgende Parameter werden nun eingetragen (Die Konfiguration entspricht meiner Installation und muss daher angepasst werden):
| Name | Wert |
| Datenbank URL: | jdbc:postgresql://localhost/dms |
| Datenbank Benutzer: | postgres |
| Datenbank Password: | 123456 |
| Button | Funktion | Beschreibung |
| Abbrechen | Abbruch (Rückgängig falls Edit-Modus) ansonsten Edit-Modus verlassen. | |
| Konfiguration speichern | Konfiguration speichern, Tabellen anlegen und Parameter schreiben. | |
| Konfiguration testen | Testet die eingegeben Parameterwerte auf deren Korrektheit | |
| Konfiguration editieren | Wechselt in den Edit-Modus | |
| Konfiguration Re-Initialisieren | Verlässt den Konfigurationsmodus und führt einen komplett Refresh der Verbindungen, etc. durch. Es erfolgt ein Redirect zum Login-Fenster. |
Über einen Druck auf de Button „Konfiguration testen“ werden die eingegeben Parameter überprüft.
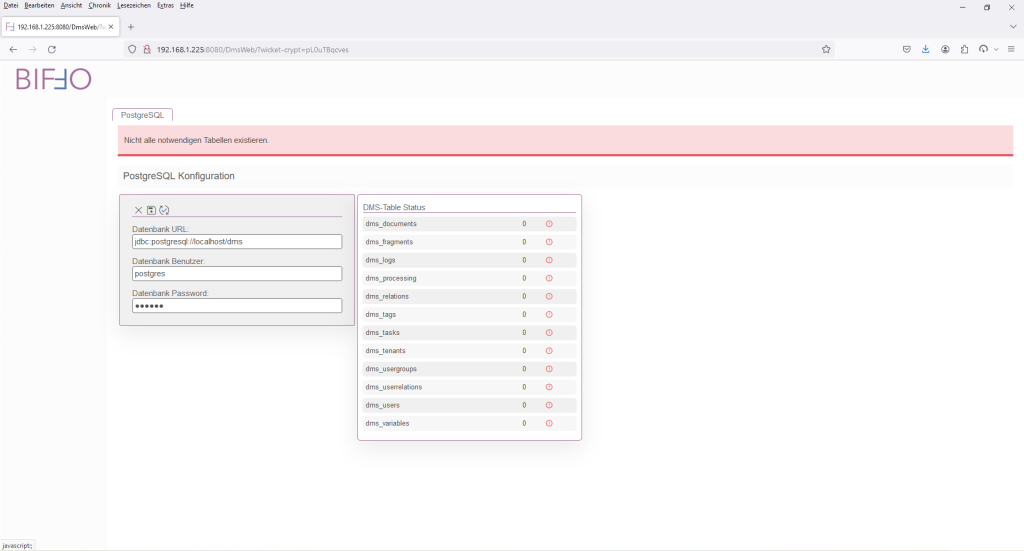
Der rote Balken liefert die Fehlermeldung, dass die jeweiligen Tabellen noch nicht vorhanden sind. Die Tabelle „DMS-Table Status“ zeigt einen Überblick um welche Tabellen es sich handelt. Die Konfiguration der Zugriffsparameter ist aber soweit OK. Anderenfalls, wäre die Tabelle „DMS-Table Status“ nicht angezeigt worden.
Ein Druck auf „Konfiguration speichern“ generiert die Tabellen und setzt die ersten Konfigurationsparameter.
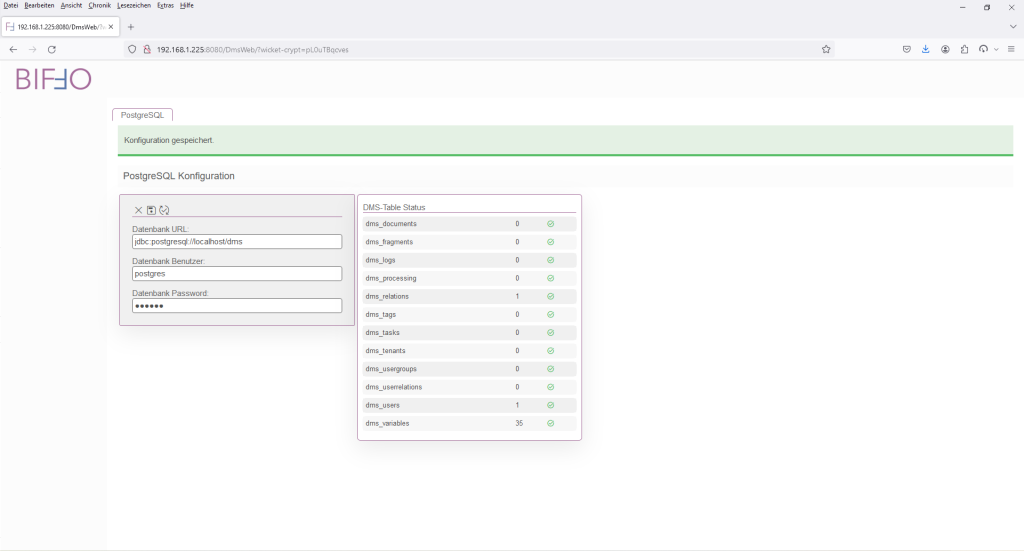
Über einen „Abbrechen“ und „Konfiguration Re-Initialisieren“ wird die Web-Applikation neu initiert und man kann sich mit dem generierten Admin-Account neu anmelden und das Setup abschliessen.
Der Default Admin Account lautet: admin/admin
Um die Konfiguration zu vervollständigen, muss in den Menu-Eintrag „Config“ gesprungen werden.
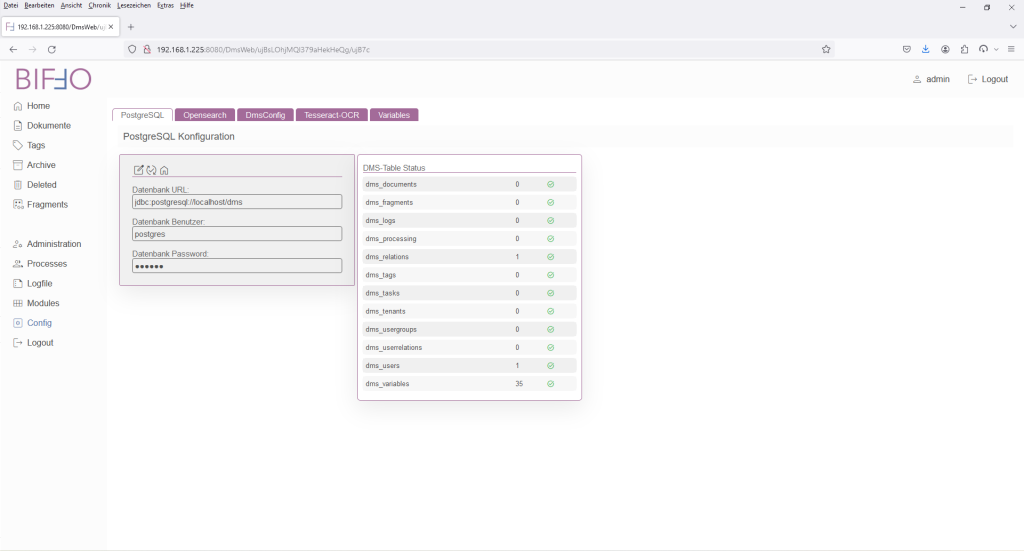
Die Einstellungen gliedern sich in vier relevante Bereiche:
| Name/Bereich | Beschreibung |
| PostgreSQL | Festlegung der PostgreSQL Datenbank und der Tabellenstruktur |
| Opensearch | Konfiguration des OpenSearch-Servers für die Suche |
| DmsConfig | Parameter Verzeichnisse und ImportTypen |
| Tesseract-OCR | Festlegung der lokal installierten Tessersact OCR Engine |
Bereich „PostgreSQL“
Hierbei handelt es sich 1:1 um das oben beschriebene Datenbank-Setup Fenster. Bei Bedarf kann aus einer laufenden Umgebung zu einer neuen Datenbank gewechselt werden. Wichtig hierbei, alle Parameter müssen erneut eingegben werden. Sollte es sich um eine bereits konfigurierte Umgebung handeln, so werden die Einstellungen aus den jeweiligen Tabellen geladen.
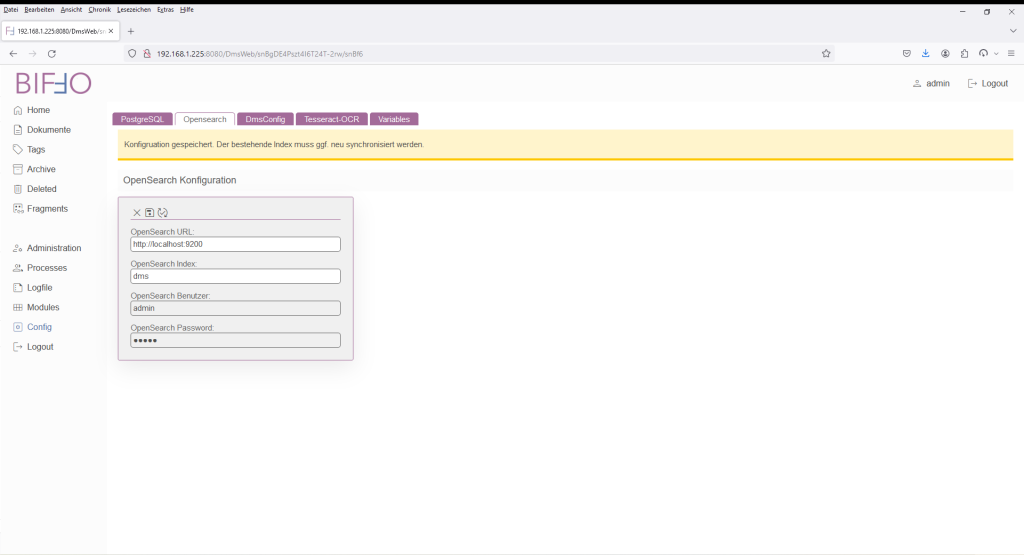
Bereich „Opensearch“
Opensearch wird verwendet um die Dokumente zu indizieren und liefert einen Suchindex für die gezielte Suche nach Dokumenteninhalten. Hierzu wird mittels der Konfiguration ein Index innerhalb des Opensearch-Server erzeugt.
| Name | Wert |
| OpenSearch URL: | http://localhost:9200 |
| OpenSearch Index: | dms |
| OpenSearch Benutzer: | admin (z.Zt. noch nicht veränderbar -> siehe Releaseplanung) |
| OpenSearch Password: | admin (z.Zt. noch nicht veränderbar -> siehe Releaseplanung) |
| Button | Funktion | Beschreibung |
| Abbrechen | Abbruch (Rückgängig falls Edit-Modus) ansonsten Edit-Modus verlassen. | |
| Konfiguration speichern | Konfiguration speichern und Index anlegen. | |
| Konfiguration testen | Testet die eingegeben Parameterwerte auf deren Korrektheit | |
| Konfiguration editieren | Wechselt in den Edit-Modus |
Um den Index anzulegen muss in den Edit-Modus gewechselt und danach die Konfiguration einfach gespeichert werden. Der grüne Balken symbolisiert das der Index erfolgreich erstellt wurde.
Ein Druck auf „Konfiguration testen“ zeigt ob die angegebenen Werte des Opensearch-Servers verwendet werden können.
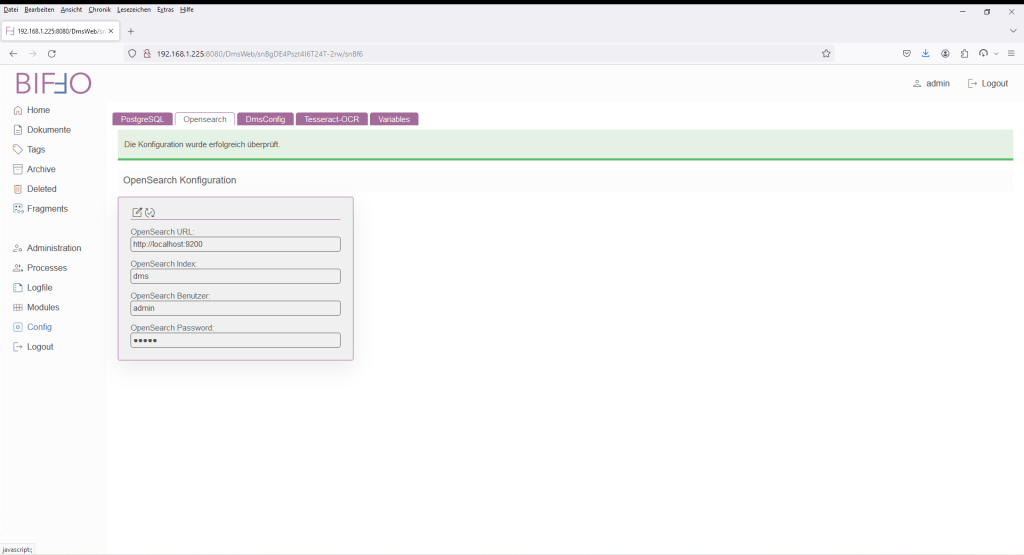
Wichtig! Die Suche kann nur so gut sein, wie auch die Texte innerhalb der bereitgestellten Dokumente, welche mittels Tesseract erkannt werden konnten.
Solle ein gelber Balken erscheinen, so wurde unter den angegebenen Werten bereits ein Index gefunden. Ob dieser Index mit denen für biffo übereinstimmt, wird nicht überprüft. Im Zweifel bitte einen neuen Namen eingeben und den Index neu erzeugen.
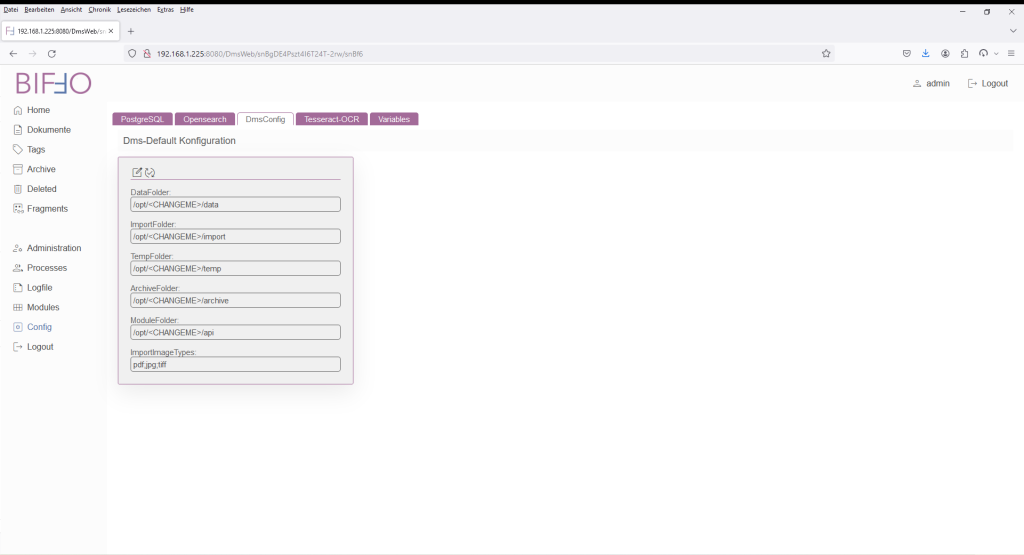
Bereich „DmsConfig“
biffo serialisiert die Dokumente nicht 1:1 in der Datenbank, sondern legt die eingelesenen Dokumente auf Dateiebene ab. Hierzu werden diverse Ablagemöglichkeiten (Verzeichnisse) benötigt.
| Parameter | Beschreibung |
| DataFolder: | In diesem Verzeichnis werden die Dokumente nach der erfolgreichen Verarbeitung abgelegt. Hierzu wird eine Struktur mit dem Aufbau ../data/YYYYMMDD erstellt. Der Zeitstempel richtet sich nach dem Zeitpunkt der Ver- bzw. Bearbeitung. |
| ImportFolder: | Der primäre Import-Ordner. In diesem Ordner werden Dokumente (siehe ImportImageTypes) aus Servern oder mittels Web-Upload verarbeitet und bei erfolgreichem Abschluß in den DataFolder überführt. Dokumente die per „cp“ abgelegt wurden, werden nicht erkannt. |
| TempFolder: | Ordner der während der einzelnen Verarbeitungsschritte als Zwischenablage verwendet wird. |
| ArchiveFolder: | Wenn gewünscht, wird nach der Verarbeitung ein ZIP-File mit dem bereitgestellten Dokument erzeugt. |
| ModuleFolder: | Bei Verwendung von API-Modulen, werden diese in diesem Verzeichnis abgelegt. |
| ImportImageTypes: | Unterstützte Import-Image Typen (Derzeit keine Bearbeitung möglich) |
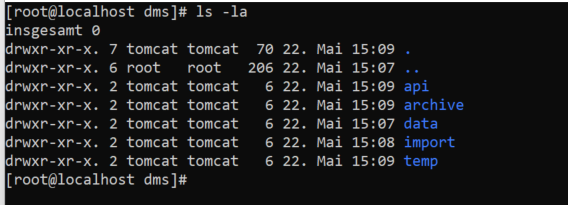
Sämtliche Ordner/Verzeichnisse müssen von dem Applikation-Server beschrieben werden können. Es empfiehlt sich dennoch diese Ordner nicht innerhalb des „Tomcat“-Server abzulegen, sondern außerhalb und dem „tomcat“-User dann die Owner Rechte zuzuweisen.
cd /opt
mkdir dms
mkdir dms/data
mkdir dms/import
mkdir dms/temp
mkdir dms/archive
mkdir dms/api
chown -R tomcat:tomcat dmsDie Ordnerstruktur sollte wie folgt aussehen:
Die Werte der erstellten Verzeichnisse werden dann analog zu der obigen Parameterstruktur eingetragen (Edit-Modus) und dann abschließend gespeichert.
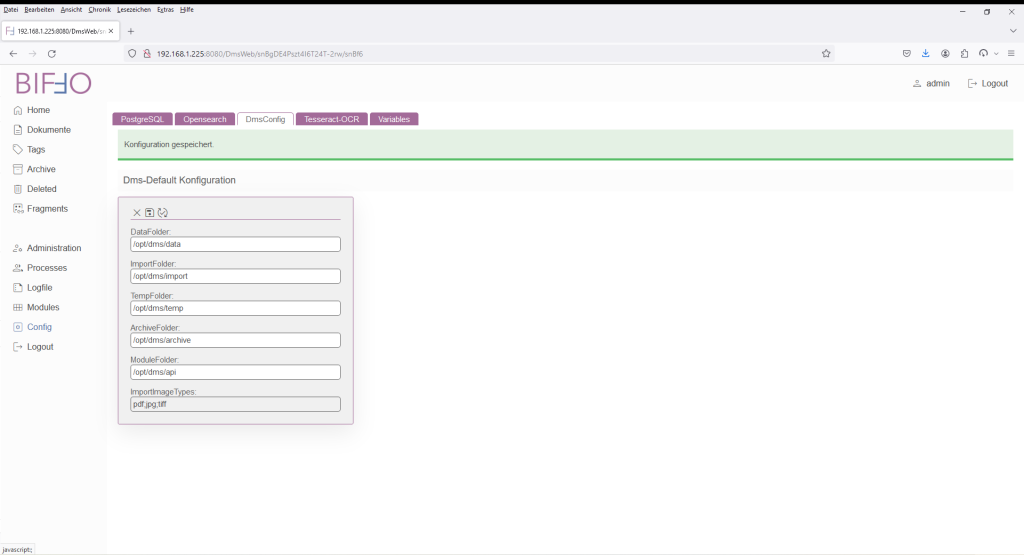
Sollte ein Verzeichnis nicht existent sein und/oder keine Berechtigung vorliegen, so erfolgt ein Hinweis an der entsprechenden Stelle.
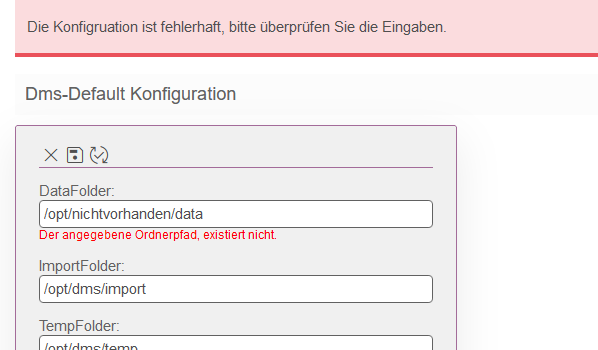
Bereich „Tesseract-OCR“
Für den Import von Bildern und Dokumenten (pdf, jpg, tiff) wird eine OCR Engine benötigt. biffo setzt hierbei auf die quelloffene Software Tesseract. Das System ermöglicht eine Umwandlung und Texterkennung mit anschließender Überführung in ein suchbares PDF. Diverse Dokumentenscanner liefern zwar eine OCR Erkennung mit, diese geschieht im Regelfall aber außerhalb irgendwo in einer Cloud-Applikation.
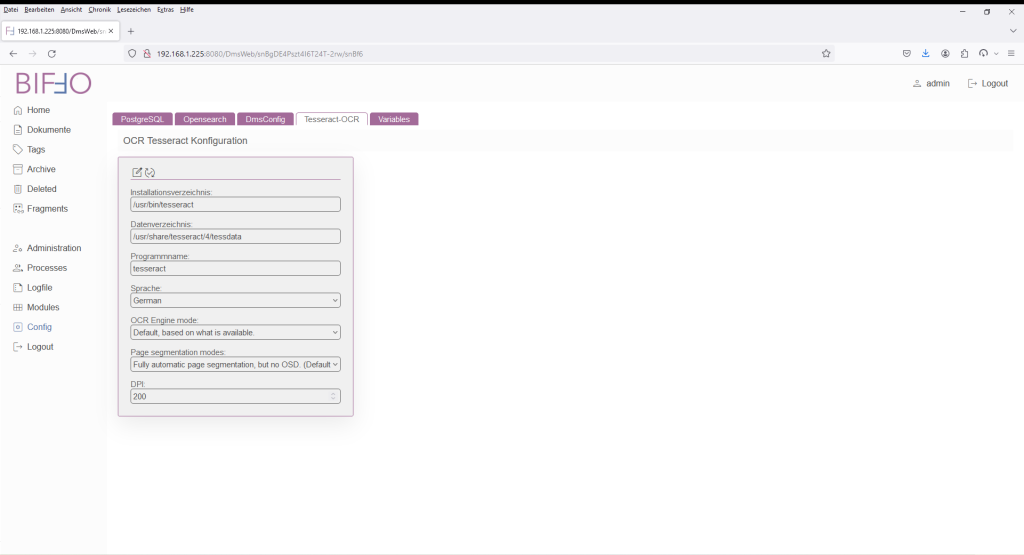
| Parameter | Beschreibung |
| Installationsverzeichnis: | In welchem Verzeichnis befindet sich die Tesseract Anwendung |
| Datenverzeichnis: | Verzeichnis mit den Lanugage-Packs. Hierüber kann auch auf ein anderes Pack (z.B. FAST) gewechselt werden |
| Programmname: | Der Befehl bzw. die Anwendung selbst. |
| Sprache: | Welches Language-Pack soll verwendet werden. Derzeit nur Deutsch und Englisch |
| OCR Engine mode: | OCR Mode von Tesseract (bitte die Tesseract Dokumentation konsultieren) |
| Page segmentation modes: | Der Modus wie Tesseract die Quell-Datei verarbeitet (bitte die Tesseract Dokumentation konsultieren). |
| DPI: | Mit welcher Auflösung werden z.B. Bilder in ein Tiff-Dokument konvertiert. Je höher die Auflösung, desto langsamer wird die Umwandlung und die Dateigröße wächst erheblich mit. |
| Button | Funktion | Beschreibung |
| Abbrechen | Abbruch (Rückgängig falls Edit-Modus) ansonsten Edit-Modus verlassen. | |
| Konfiguration speichern | Konfiguration speichern und Index anlegen. | |
| Konfiguration testen | Testet die eingegeben Parameterwerte auf deren Korrektheit und versucht das Programm Tesseract zu starten. | |
| Konfiguration editieren | Wechselt in den Edit-Modus |
Nachdem die Einträge vollzogen wurden, kann die Konfiguration getestet und gespeichert werden.
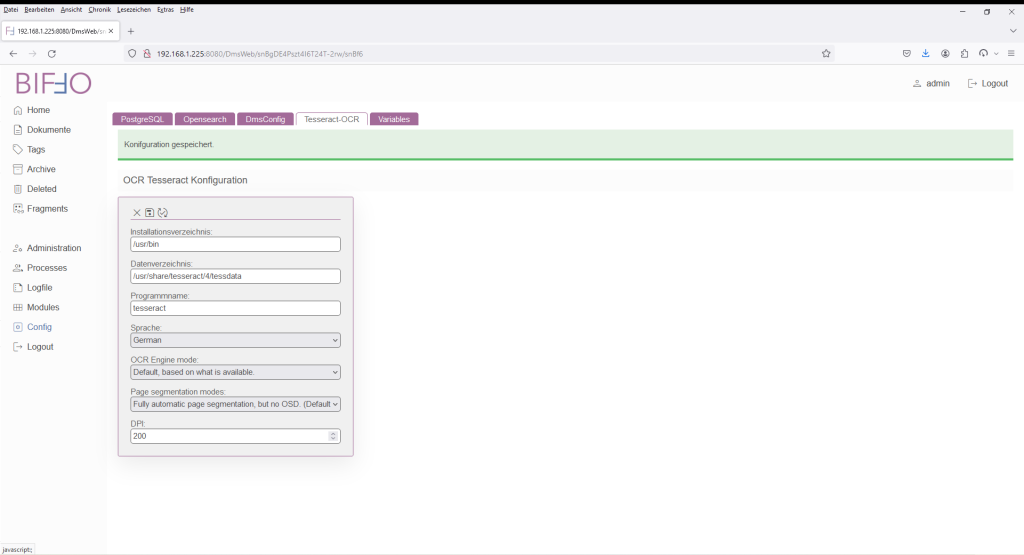
Bereich „Variablen“
Dieser Bereich zeigt die gespeicherten Parameter (u.A. Password im Quelltext) und sollte nur auf Anweisung modifiziert werden. Daher an dieser Stelle keine Erklärungen.
Erstes Dokument importieren
Wenn alle Einstellungen vollzogen wurden, kann versucht werden das erste Dokument in biffo zu importieren.
Aufgrund der nicht vorhandenen Verzeichnisse, muss erstmalig der „Default PDF Importer“ per Hand gestartet werden. Dieses geschieht im Mneü „Administration“ und dort unter dem Reiter „Importers“.
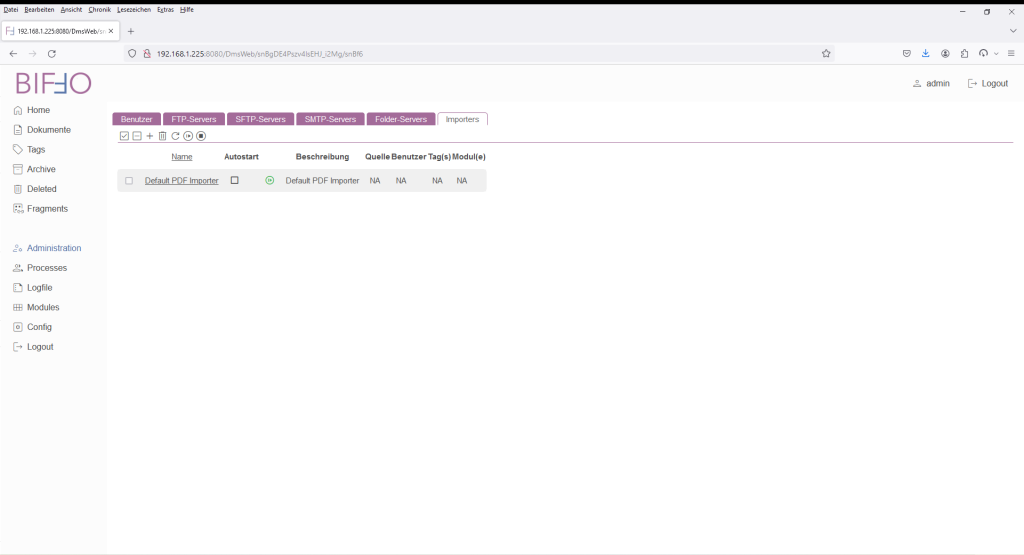
Ein Druck auf den grünen „Startknopf“, startet den Web-Importer. Für den Fall das der Button weiterhin auf der Farbe grün verweilt, bitte mit F5 die Seite aktualisieren. Der Button sollte dann auf die Farbe rot gewechselt haben.
Anschließend kann im Menü „Home“ der „Default PDF Importer“ verwendet werden. Entweder über einen Druck auf „Select Files“ mittels Filedialog ein Dokument auswählen oder per D&D ein Dokument auf den Importer ziehen.
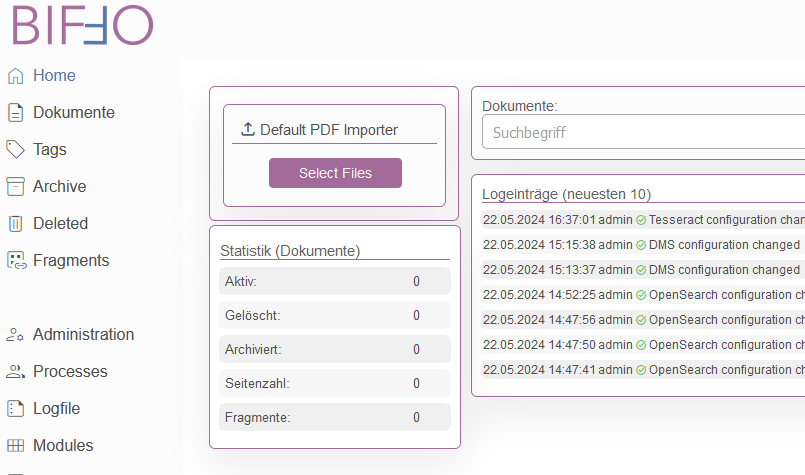
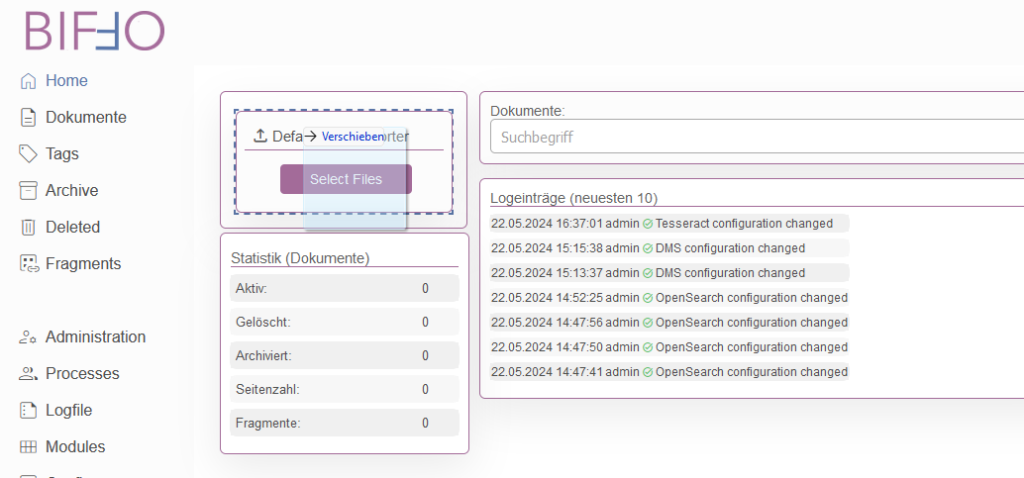
Nach Selektion bzw. D&D erfolgt der Start der Default-Verarbeitungskette.
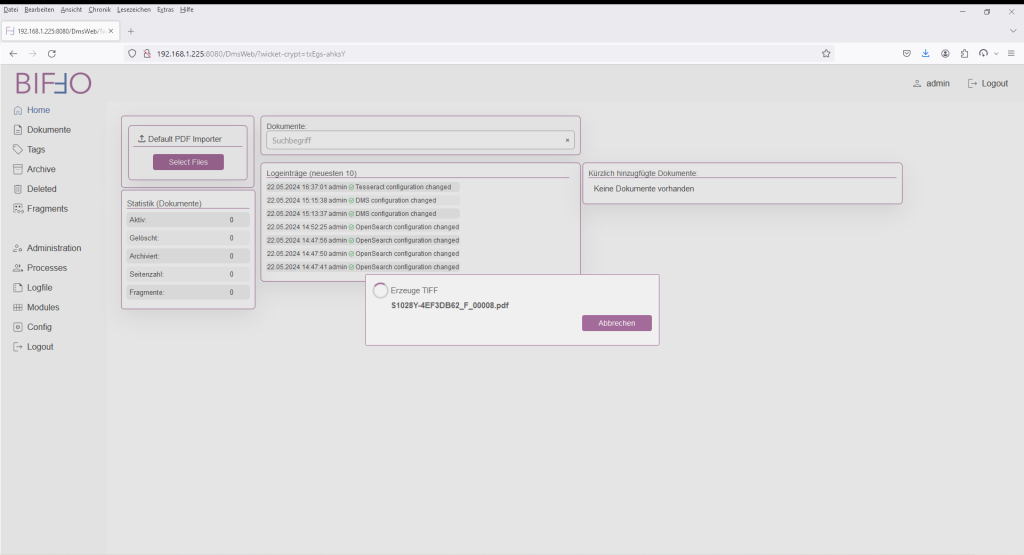
Nach Beendigung der Prozesskette ohne Fehlermeldung (grüner Balken), ist das Dokument erfolgreich in das System importiert worden.
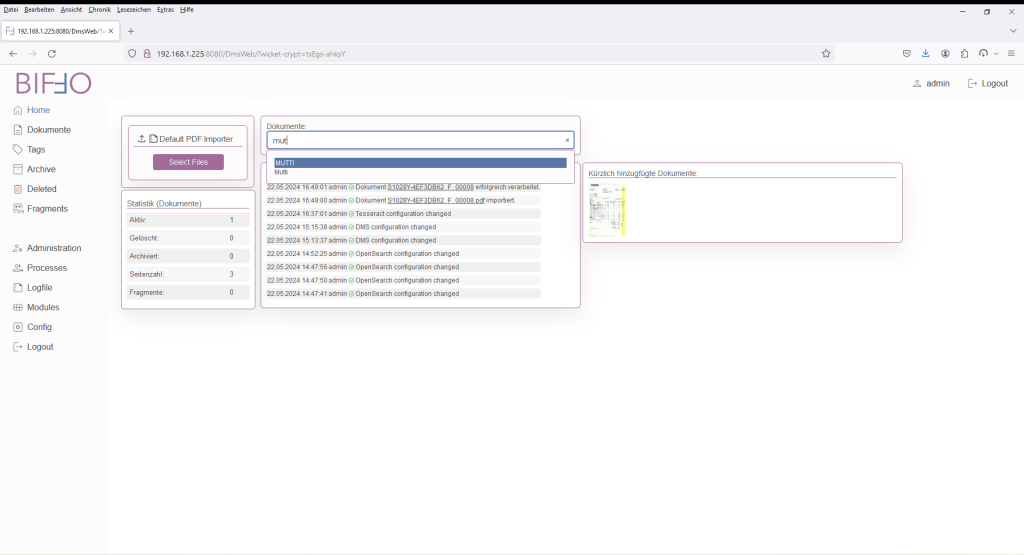
Hiermit endet die erstmalige Installation.
Weitere Informationen befinden sich in Nutzung biffo.