Beispiel Entity-Tagger
Wie im Vorfeld bereits beschrieben, können Inhalte von Dokumenten für die automatische Zuordnung von „Title“ (Dokument-Name), „KeyWords“ und „DocumentDate“ (Dokumenten-Datum) verwendet werden.
Das Modul soll in einem Dokument nach dem Text „Vodafone“ suchen, in die Keywords dann „Vodafone“ eintragen und dann abschließend den Tag „Vodafone“ zuweisen.
Das Beispiel beruht auf Eclipse (der Autor nutzt seit Jahren Eclipse und ist damit zufrieden).
Für die Umsetzung werden die Jar-File „dmsapi.jar“ und „dms.jar“ benötigt.
Um das Modul dem System bekannt zu machen, müssen einige Annotation’s bei der Deklaration gesetzten werden:
| Annotation | Verwendung (Target) | Beschreibung |
| @ProcessName | TYPE | Name des Moduls z.B. @ProcessName(value = „Vodafone Tagger“) |
| @ProcessAuthor | TYPE | Name des Autors, die Webseite, die Major und Minor-Version z.B. @ProcessAuthor(author = „mlange“, url = „www.biffo.de“, major = 0, minor = 1 ) |
| @Description | TYPE | Eine Beschreibung des Moduls z.B. @Description(„Sucht nach dem Text Vodafone“) |
| @ConfiguredTag | FIELD | Wie soll der zugeordnete Tag aussehen z.B. @ConfiguredTag(tagvalue=“Vodafone“, bgcolor=“#ff2020″, fgcolor=“#ffffff“) |
Der Definitionsblock würde dann wie folgt umgesetzt:

Die einzig wirklich relevanten Funktionen in dem Beispiel sind:
| Funktion | Beschreibung |
| addTag | Tags werden vor Ausführung mit den bereits existierenden Tags („Menü->Tags“) abgeglichen und an die Funktion zur Verwendung zugewiesen. Bei einem erfolgreichen Erkennen der Funktion doText erfolgt dann die Zuordnung des definierten Tags über getTags. |
| doText | Hauptroutine zur Bestimmung der Inhalte. Bei Ausführung werden vom System nur die erste Seite oder alle Dokument-Seiten übergeben. In diesem Beispiel wird gezielt nach dem Fragment „Vodafone“ gesucht. Bei einem Treffer erfolgt die Rückgabe als „True“ ansonsten „False“. |
| getKeyWords | Beinhaltet die KeyWords, welche der Entität Dokument zugeordnet werden sollen |
| getTags | siehe addTag |
Das beschriebene Modul könnte daher wie folgt implementiert werden:
package de.biffo.tagger;
import java.io.Serializable;
import java.util.Date;
import java.util.LinkedList;
import java.util.List;
import org.biffo.dms.api.ConfiguredTag;
import org.biffo.dms.api.Description;
import org.biffo.dms.api.IDocumentEntity;
import org.biffo.dms.api.ProcessAuthor;
import org.biffo.dms.api.ProcessName;
import org.biffo.dms.entity.Fragments.Fragment;
import org.biffo.dms.entity.Tags.Tag;
@ProcessName(value = "Vodafone Tagger")
@ProcessAuthor(author = "mlange", url = "www.biffo.de", major = 0, minor = 1)
@Description("Sucht nach dem Text Vodafone")
public class vodafonetagger implements IDocumentEntity, Serializable {
private static final long serialVersionUID = 1L;
@ConfiguredTag(tagvalue="Vodafone", bgcolor="#ff2020", fgcolor="#ffffff")
public Tag tVodafone;
private String keyWords;
private List<Tag> lstTags = new LinkedList<Tag>();
@Override
public void addTag(Tag tagToAdd) {
lstTags.add(tagToAdd);
}
@Override
public boolean doText(String inputText) {
if(inputText==null) return false;
if(inputText.length()==0) return false;
if(inputText.toLowerCase().contains("vodafone")) {
keyWords ="Vodafone";
return true;
}
return false;
}
@Override
public Date getDocumentDatum() {
return null;
}
@Override
public List<Fragment> getFragments() {
return null;
}
@Override
public String getKeyWords() {
return keyWords;
}
@Override
public double getScore() {
return -1;
}
@Override
public List<Tag> getTags() {
return lstTags;
}
@Override
public String getTitle() {
return null;
}
@Override
public boolean hasFragments() {
return false;
}
@Override
public void init() throws Exception {
}
}
Nachdem das Modul als JAR exportiert wurde, kann es über den Modul-Upload dem System bekannt gemacht und genutzt werden.
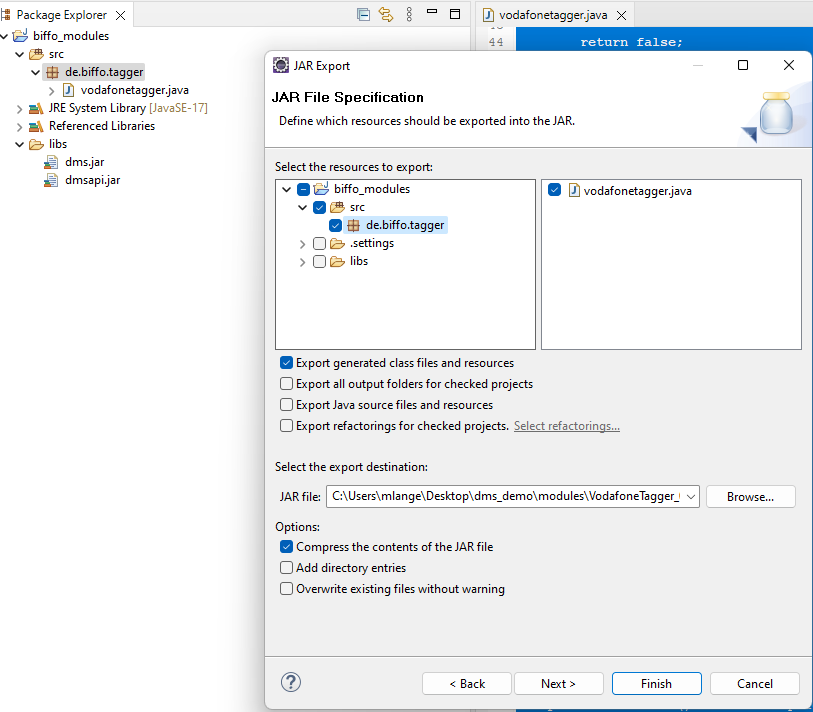
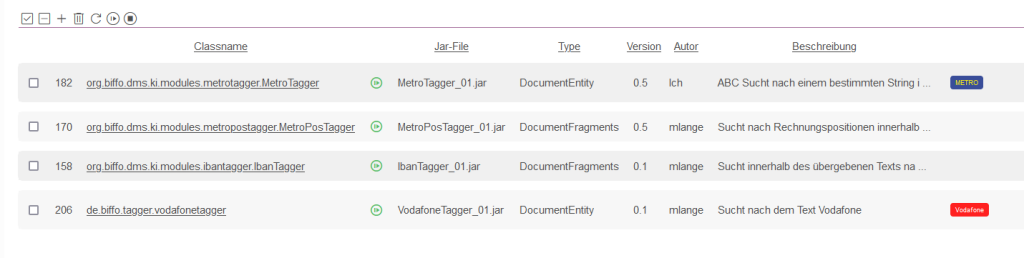
Das Modul lässt sich nach einem Test (siehe Moduls / Test Modul) auf ausgewählte Dokumente, innerhalb der Dokumentansicht, oder in einer Import-Routine nutzen.
- Drag&Drop „de.biffo.tagger.vodafonetagger“ auf ein Dokument.
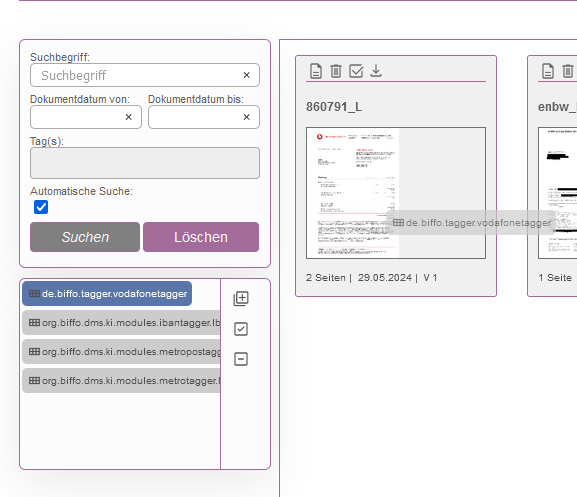
2. Modul startet auf dem jeweiligen Dokument.
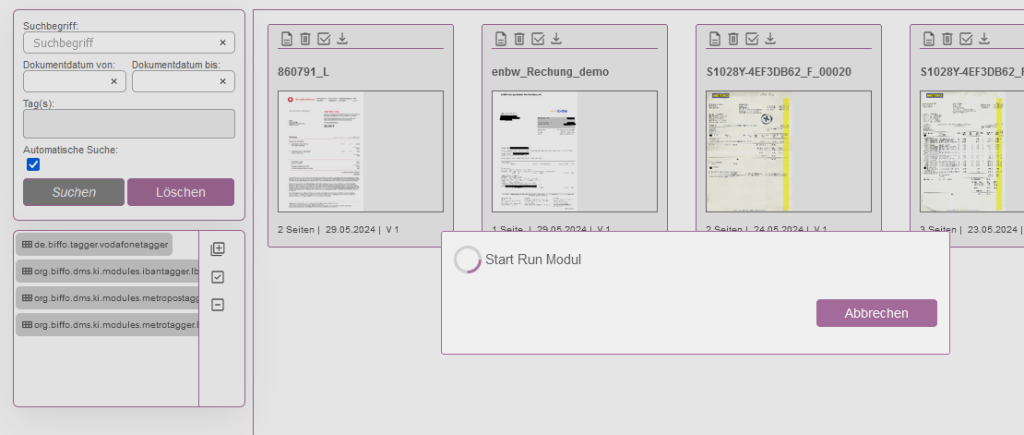
3. Nach erfolgreicher Erkennung des Texts „Vodafone“
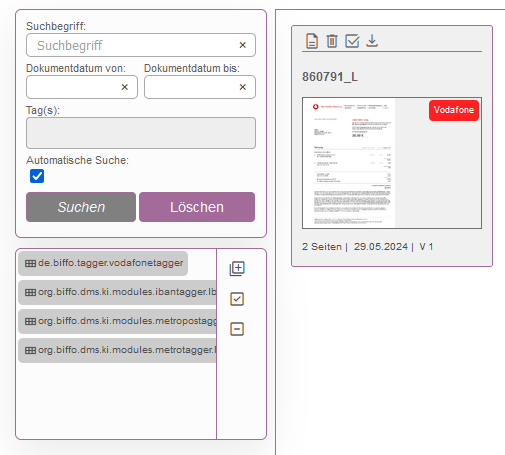
Bereitgestellte Funktionen von „IDocumentEntity“ und deren Nutzung:
addTag
Beim Starten des Moduls z.B. mittels Import-Prozess, werden Tags die mittels @ConfigureTag dem Modul zugeordnet wurden, innerhalb der Tabelle dms_tags ermittelt und bei erfolgreichem Abschluss der „doText“ Routine dem Dokument zugeordnet. Sollte die Farbgebung innerhalb der Applikation geändert worden sein, so werden FG- und BG-Farben aus dem System herangezogen. Die Farbgebung innerhalb @ConfigureTag hat keinen Einfluss mehr.
| Eingabe | Rückgabe |
| Tag | void |
doText
Routine zur Überprüfung der einzelnen Seitentexte des jeweiligen Dokumentes, auf den das Modul angewendet wurde. Das Modul kann für die Verwendung Aller oder nur der ersten Seite in den Moduleinstellungen konfiguriert werden.
Bei Rückgabe von „true“ werden die Funktionen „getDocumentDatum“, „getKeyWords“ und „getTitle“ auf das gerade im Zugriff befindliche Dokument angewendet und die Entität entsp. abgeändert. Ferner wird die Routine „getTags“ und „getFragments“ ausgeführt und im Bedarfsfalls die Werte übermittelt.
| Eingabe | Rückgabe |
| String | boolean |
getDocumentDatum
Liefert ein dem Dokument zuzuordnendes Datum (Dokumenten Datum). Falls Rückgabe „null“ wird der Datumswert nicht geändert.
| Eingabe | Rückgabe |
| None | Date |
getFragments
Liefert eine Liste mit generierten Fragmenten, die während des Aufrufs der „doText“ Funktion erstellt wurden. Die generierten Fragmente werden vor Speicherung auf ein mögliches Vorhandensein überprüft und ggf. mit bestehende Fragmente ersetzt und mit dem Dokument verknüpft.
| Eingabe | Rückgabe |
| None | List<Fragment> |
getKeyWords
Liefert dem Dokument zuzuordnende Keywords. Bei der Rückgabe von „null“ werden die KeyWords nicht verändert.
| Eingabe | Rückgabe |
| None | String |
getScore
Liefert einen %-Wert des gefundenen Ergebnisses.
Derzeit noch keine Verwendung.
| Eingabe | Rückgabe |
| None | double |
getTags
Liste mit Tags, welche dem Dokumente im Falle eines positiven „doText“ zugeordnet werden solle. Die Liste wird automatisch vor Ausführung.
| Eingabe | Rückgabe |
| None | List<Tag> |
getTitle
Liefert ein Textwert, der dem Dokument als Dokument-Name zugeordnet werden soll. Falls Rückgabe „null“ wird der Name nicht geändert.
| Eingabe | Rückgabe |
| None | String |
hasFragments
Positive Rückgabe, falls Fragmente dem Ergebnis der „doText“ Funktion zugeordnet werden können. Falls Fragment aufgebaut wurden und die Rückgabe „false“ liefert, erfolgt keine Verarbeitung der Fragmente.
| Eingabe | Rückgabe |
| None | boolean |
init
Wird beim Laden des Moduls in den Hauptspeicher ausgeführt. Hierüber können z.B. dynamisch Open-NLP Modelle geladen werden.
| Eingabe | Rückgabe |
| None | None |
Beispiel Metro-Tagger
Der Metro-Tagger sucht nach dem vorher bestimmten Muster „25.04.2020/048/0/0/0004/021615“ innerhalb der übergebenen Texte. Das verwendete NLP-Modell wurde anhand von 6 vorhandenen und eingescannten Metro-Rechnungen trainiert und dem Tagger innerhalb des JAR-Files mitgegeben (siehe „init()“). Der Code ist im Vergleich zu dem Vodafone-Tagger etwas umfangreicher, dennoch entfällt die aufwendige Logik mittels RegEx und anschließenden Parsing.
@ProcessName(value = "Metro Tagger")
@ProcessAuthor(author = "mlange", url = "www.biffo.de", major = 0, minor = 5)
@Description("Sucht nach einem bestimmten String innerhalb einer Metro Rechnung "
+ "und liefert entsp. die gewünschten Informationen zurück")
public class MetroTagger implements IDocumentEntity, Serializable {
private static final long serialVersionUID = 1L;
// 25.04.2020/048/0/0/0004/021615
@ConfiguredTag(tagvalue = "METRO", bgcolor = "#394d99", fgcolor = "#f8ed07")
public Tag tag1;
// Datumsformat für den Dokument-Name
private final static SimpleDateFormat _sdf = new SimpleDateFormat("dd.MM.yyyy");
// Aufbau des Dokumenten-Namens
private String docTitlePattern="METRO_RECHNUNG_<DocumentDate>";
private Date documentDatum;
private String keyWords;
private List<Tag> lstTags = new LinkedList<Tag>();
private List<Fragment> lstFragments = new LinkedList<Fragment>();
// Open-NLP Routinen
private transient TokenNameFinderModel _model;
private transient NameFinderME _nameDetector;
private double score;
public MetroTagger() {
}
@Override
public void init() throws Exception {
// Laden des NLP-Models direkt aus dem JAR-File
String packageName = this.getClass().getPackageName();
packageName = packageName.replaceAll("\\.", "/");
InputStream input = this.getClass().getClassLoader().getResourceAsStream(packageName+"/metro_NAIVEBAYES.bin");
// Initialisierung der Open-NLP Funktionen
_model = new TokenNameFinderModel(input);
_nameDetector = new NameFinderME(_model);
}
@Override
public String getTitle() {
String temp = docTitlePattern;
if(documentDatum!=null) {
temp = temp.replaceAll("<DocumentDate>", _sdf.format(getDocumentDatum()));
}
return temp;
}
@Override
public Date getDocumentDatum() {
return documentDatum;
}
@Override
public String getKeyWords() {
return keyWords;
}
@Override
public double getScore() {
return score;
}
@Override
public boolean doText(String input) {
boolean found=false;
try {
clearAll();
String contentIn = input;
// Übergabe des Seitentextes an die Open-NLP Funktion
String [] sentence = WhitespaceTokenizer.INSTANCE.tokenize(contentIn);
Span nameSpans[] = _nameDetector.find(sentence);
// Falls ein Fragment erkannt wurde, wird dieses weiterverabeitet
if(null!=nameSpans && nameSpans.length>0) {
Span nameSpan = nameSpans[0];
score = nameSpan.getProb();
int fromWord =nameSpan.getStart();
int toWord=nameSpan.getEnd();
StringBuilder sb = new StringBuilder();
for(int i=fromWord;i<toWord;i++) {
sb.append(sentence[i]);
sb.append(" ");
}
// Überprüfung ob das gefundene Fragment auch den Aufbau einer Metro-Rechnungsnummer hat
found= parseTag(sb.toString(), nameSpan);
}
_nameDetector.clearAdaptiveData();
}catch(Exception e) {
}
return found;
}
private boolean parseTag(String strIn, Span nameSpan) {
if(null==strIn || strIn.isEmpty()) return false;
String temp = strIn.trim();
temp = temp.replaceAll(" ", "");
Fragment fragment = new Fragment();
fragment.setErstelltVon(this.getClass().getSimpleName());
fragment.setGeaendertVon(fragment.getErstelltVon());
fragment.setFragmentname(nameSpan.getType());
fragment.setFragmentvalue(strIn);
fragment.setValid(true);
fragment.setFragmenttype("IDocumentFragments");
fragment.setProbability(nameSpan.getProb());
fragment.setPage(-1);
lstFragments.add(fragment);
// Pattern dd.MM.yyyy/000/0/0/0000/000000
String strArr[] = temp.split("\\/");
if(strArr.length!=6) return false;
try {
documentDatum = _sdf.parse(strArr[0]);
return true;
}catch(Exception e) {
}
return false;
}
private void clearAll() {
keyWords = null;
documentDatum = null;
score = 0;
lstFragments.clear();
}
@Override
public List<Tag> getTags() {
return lstTags;
}
@Override
public void addTag(Tag tagToAdd) {
lstTags.add(tagToAdd);
}
@Override
public boolean hasFragments() {
if(lstFragments.size()>0) return true;
return false;
}
@Override
public List<Fragment> getFragments() {
return lstFragments;
}
}Der Aufbau und das Trainieren von NLP-Modellen ist nicht Bestandteil dieser Dokumentation.